8 mins read
This is the third and last post in our pre-main Zephyr series.
In the previous articles (first, second), we explored the resources Zephyr uses to bring up ARM Cortex-M
CPUs after a reset.
In the last episode, we examined z_prep_c and unfolded how Zephyr defines and uses initialization
functions at different stages of the boot process.
After initializing early init calls, Zephyr’s z_cstart function hands over control to the
architecture-specific initialization function arch_kernel_init. Its source code for ARM Cortex-M
CPUs is under arch/arm.
This function is responsible for many things, mainly:
- Setting up the interrupt stack. As one would expect, the OS gives the user
the option to set its size to a custom value by overriding the Kconfig
variable
CONFIG_ISR_STACK_SIZE. - Setting up system exceptions (PendSV, SVCall, SysTick, etc.) and enabling faults by writing to dedicated registers.
- Setting up the CPU behavior when idle in
z_arm_cpu_idle_init: even masked/pending interrupts can wake the CPU from WFE. - Setting up the MPU for chips that embed it.
In multithreaded systems, z_cstart then initializes the “dummy” thread, which
acts as a safe placeholder before real threading starts.
Next, the function initializes internal device state metadata by calling z_device_state_init, to
ensure the instances are in a valid state before executing user logic.
Then come SoC and board early init hooks: soc_early_init_hook and board_early_init_hook.
Recall that arch_cache_init is an empty stub for ARM Cortex-M-based MCUs? These are often used for
low-level hardware setups not covered by standard init levels.
Take the nRF53 microcontroller (ARM Cortex-M33) as an example: its soc_early_init_hook enables
instruction and data caches very early:
// soc/nordic/nrf53/soc.c
void soc_early_init_hook(void) {
#if defined(CONFIG_SOC_NRF5340_CPUAPP) && defined(CONFIG_NRF_ENABLE_CACHE)
#if !defined(CONFIG_BUILD_WITH_TFM)
nrf_cache_enable(NRF_CACHE);
#endif
// ...
}
In contrast, boards like the Nano 33 BLE, based on a simpler nRF52840 SoC, do not implement either of these hooks.
Once again, Zephyr proceeds to calling init functions for two successive
levels: PRE_KERNEL_1 and PRE_KERNEL_2:
z_sys_init_run_level(INIT_LEVEL_PRE_KERNEL_1);
#if defined(CONFIG_SMP)
arch_smp_init();
#endif
z_sys_init_run_level(INIT_LEVEL_PRE_KERNEL_2);
The current codebase has dozens of PRE_KERNEL_1 routines (obviously many of
them are “config-gated”), their common characteristics mainly revolve around:
- Initializing “dependency-less” devices that solely rely on the onboard hardware components.
- Setting up basic system resources (clocks, power, memory, etc).
- Configuring console/debug infrastructure (UART, RTT, JTAG, etc).
The fact that arch_smp_init call is positioned between PRE_KERNEL_1 and
PRE_KERNEL_2 isn’t a coincidence: it’s one of the main differences between
the two levels:
PRE_KERNEL_2 is conceptually similar to PRE_KERNEL_1; it still runs on
the interrupt stack, with no kernel services available. But the twist is the fact that it’s
expecting a multicore-aware context, where all cores have been initialized, which is exactly what
arch_smp_init does.
However, this is mostly irrelevant in the context of this series focusing on
the traditionally single-core ARM Cortex-M CPUs, unless used in custom designs or vendor-specific
multi-core implementations.
Following this, stack canary is set up by filling the __stack_chk_guard with a random value in
builds that enable it. This is a common technique used for stack overflow protection.
Fast forward, the last part is more interesting, let’s break it down.
#ifdef CONFIG_MULTITHREADING
switch_to_main_thread(prepare_multithreading());
#else
#ifdef ARCH_SWITCH_TO_MAIN_NO_MULTITHREADING
ARCH_SWITCH_TO_MAIN_NO_MULTITHREADING(bg_thread_main,
NULL, NULL, NULL);
#else
bg_thread_main(NULL, NULL, NULL);
irq_lock();
while (true) {
}
#endif
#endif
The goal is to switch to main(), there are three cases to consider.
Multithreading is disabled
When multi-threading is not available, there are two options.
CPU-level switch to main
Zephyr allows the definition of an architecture-specific function
ARCH_SWITCH_TO_MAIN_NO_MULTITHREADING, dedicated to switching to main. Only three architectures
define it: ARC, RISC-V, and ARM Cortex-M.
Remaining cases
As a fallback, bg_thread_main is called with NULL arguments to spin-off main.
Multithreading is enabled
This is the most common configuration, in particular for Cortex-M-based SoCs and boards.
First, the scheduler’s ready queue (_ready_q) is initialized, a thread main is created with
a dedicated stack in _THREAD_SLEEPING state by default. Then, the “sleeping” flag is cleared and
it is queued as “ready” (i.e. runnable) in the kernel’s scheduler, before switching to it from
“dummy” thread.
This is a very high-level overview of the final steps before reaching main.
In fact, thread creation is one of the few places where Zephyr truly dips into architecture-specific
low-level behavior. After all, this series was meant to focus on ARM Cortex-M CPUs, so let’s take
a step back and see what we can learn from it.
The arch_new_thread function prepares a new thread’s with a proper initial state so that when it’s
first scheduled, it can execute correctly with the processor’s context switching mechanism. The most
important part of it is arguably the assembly block that directly performs the switch. Before
it, it’s all about setting up global variables and pointers with main thread data (FPU, TLS, etc.),
stack protection, and so forth. We won’t cover that part.
What matters most is this portion of code:
__asm__ volatile("mov r4, %0\n" /* force _main to be stored in a register */
"msr PSP, %1\n" /* __set_PSP(stack_ptr) */
"movs r0, #0\n" /* arch_irq_unlock(0) */
"ldr r3, =arch_irq_unlock_outlined\n"
"blx r3\n"
"mov r0, r4\n" /* z_thread_entry(_main, NULL, NULL, NULL) */
"movs r1, #0\n"
"movs r2, #0\n"
"movs r3, #0\n"
"ldr r4, =z_thread_entry\n"
/* We don’t intend to return, so there is no need to link. */
"bx r4\n"
/* Force a literal pool placement for the addresses referenced above */
".ltorg\n"
:
: "r"(_main), "r"(stack_ptr)
: "r0", "r1", "r2", "r3", "r4", "ip", "lr", "memory");
Fortunately the code is well-documented so it makes things easier to understand. We can note a few additional things:
- Switching to assembly at this stage is not really a choice. This can’t be done in pure C as it requires precise low-level control over registers and CPU state.
- This is the first time
PSPis used, marking a key shift from early init to C application runtime. Since reset,MSPwas used for all operations.msr PSP, %1sets the new stack pointer to the top of the stack previously allocated formain. - Saving
_maininr4beforehand is mandatory to make sure it is retrieved after the transition between stacks. mainis invoked through a wrapper function (_main) that is in turn passed toz_thread_entrywith 3 additional arguments that are all set toNULL. Prior to that, interrupts are enabled, and eventually, a linkless branch instruction is used, since no return is expected.- A small detail worth noting is the use of a not-so-known assembler directive called
.ltorg. It ensures that function addresses used earlier in the assembly, namelyz_thread_entryandarch_irq_unlock_outlined, are not placed too far away in memory so the CPU can load them efficiently. It is a low-level concern that’s mostly important in ARM processors that have limited addressing ranges, especially in Thumb mode.
A high-level overview
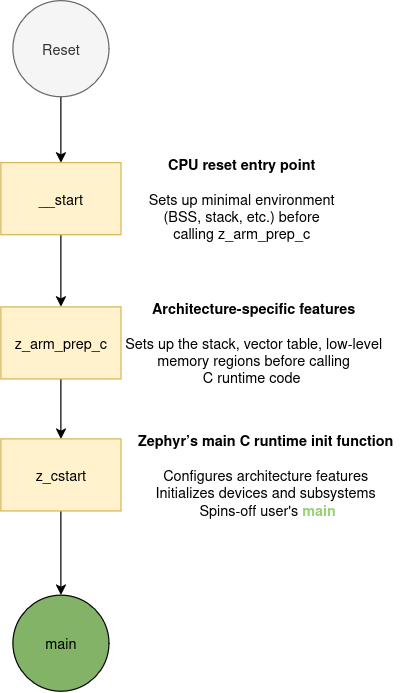
As a summary, this high-level diagram gives a visual representation of the boot flow from power-on
until main, with a special focus on the steps we covered in the series: __start, z_arm_prep_c,
and z_cstart.
Somes words to end
I’m a firm believer that good software engineers take the time to dig into the nitty-gritty details to truly master their stack. As someone still new to Zephyr, I wrote this series to better understand the source code, especially through the lens of Cortex-M startup files.
This deep dive was as much an effort to learn as it was to share. If it helped someone else make
sense of the system, even a little, then it was worth writing.
If you spot anything inaccurate, misleading, or unclear, please reach out, I would genuinely
appreciate the opportunity to improve and learn from you.